One
of the most important concepts in Computer Science is sorting, since it makes
lists and collections much easier to deal with. Most introductory programming
courses teach the common sorting algorithms of selection sort, merge sort, and
quick sort, like CSC148H1. Elaborating a bit more on each of these ...
Selection
sort iterates through the list, finding the largest element and placing it at
the end of the list. After doing this on a list of length n, the greatest element is in place, and so selection sort then
continues on the sublist of length n - 1.
One at a time, the maximum element of the remaining list is put in its proper
place. A total of n - 1 passes are
required, giving selection sort an efficiency of O(n2). This is the sort I like to use when playing card
games like Crazy Eights or President, except I think it's a lot easier to do
this as a human being because I don't have to individually pass through each
card, but can just see which card is the greatest.
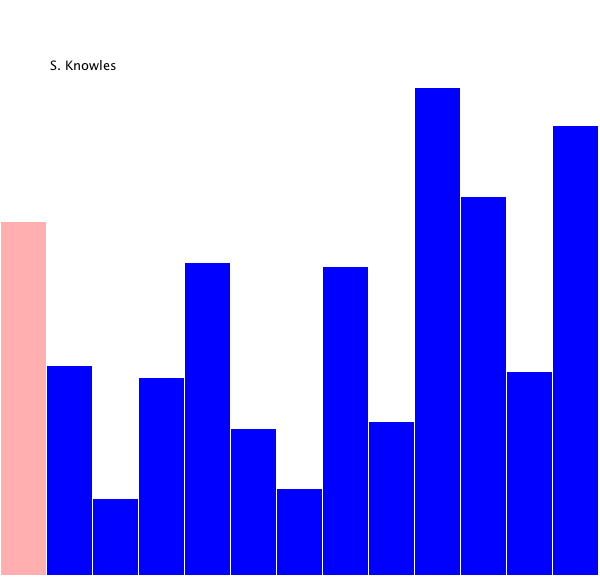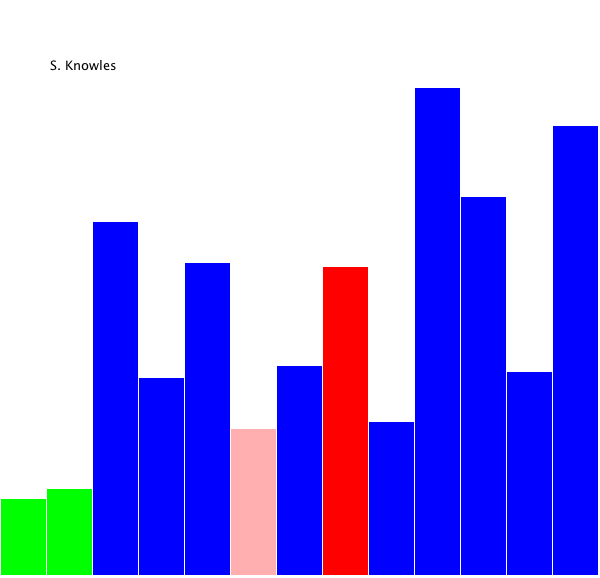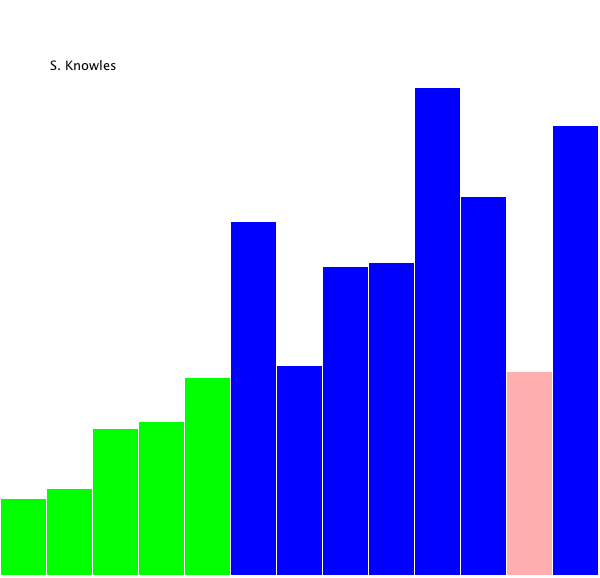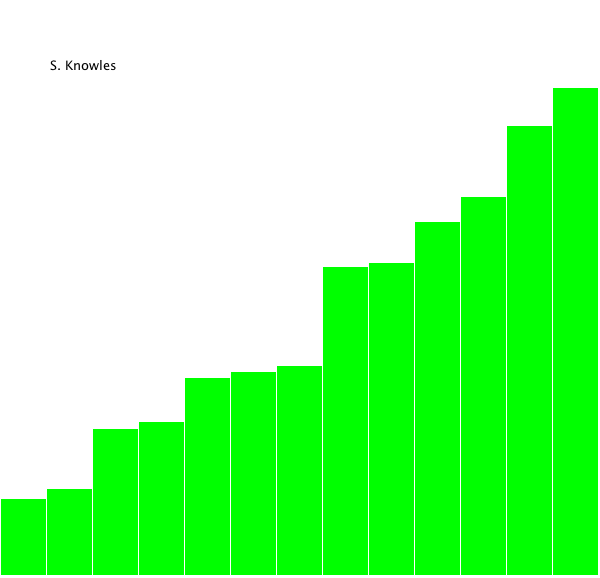
Here's
a visual example of selection sort, which instead finds the minimum element and
places it at the beginning of the list:
Merge
sort (and quick sort, too) are more efficient than selection sort by using a
divide-and-conquer strategy, eliminating the need to make passes through the
entire list. Merge sort repeatedly breaks the list into halves until it has
sublists of only length 1, and then uses a helper method to merge pairs of
sublists together in the proper order. So, the list is completely broken down
into pieces and then reconstructed, piece by piece, eventually recreating the
whole list in sorted order. It's much easier to understand this visually:
It
takes log(n) steps to break the lists
into pieces, and then it needs to merge all n
elements, so the efficiency of merge sort is O(n log n).
Quick
sort is my personal favourite. Using a pivot value, quick sort breaks a list
into two sublists, one with elements greater than or equal to the pivot value and
one with elements less than the pivot value. It continuously breaks down the
list in this way, and when it can no longer be broken down, it brings together
all the sublists that were created to reconstruct the list in sorted order.
Although I learned quick sort in Java first back in high school, learning it
again in Python has made it my favourite for a few obvious reasons: firstly,
unlike other sorting algorithms, quick sort doesn't require any helper function
and can thus save memory and space that way. Secondly, in Python, the ternary
if, list comprehension technique, and one-line return statement literally make
this sort a one-liner. Quick sort's efficiency is the same as merge sort's: O(n log n).

One
potential problem of the quick sort algorithm is the choice of the pivot value.
If the pivot value is repeatedly the greatest or least element in the list
being examined, then quick sort's efficiency will be reduced to O(n2). As mentioned in class,
one way to prevent this is to choose a random value from the list to act as a pivot,
but this still has a (very slight) chance of selecting a bad pivot value.
Another solution that could be used (but that may not be the best trade-off
because of the extra iterations/operations required) is to find the values of
the first, last, and middle elements of the list, and to choose the median of these as the pivot (guaranteeing that you don't have the worst pivot value
possible).
Until
now, efficiency has never really been my primary concern. I'd rather get a
working solution first than try to find both an efficient and correct solution
at once. Once I have a working solution, then
I try to make my code more efficient. However, I'm realizing that this isn't
the best approach to programming, and that the best solution is more desired
than a great solution. Sure, both will accomplish the same goal, but regarding the inner workings of a computer, it is much better if less time and space are consumed in the process. If I only looked for a quick, easy solution to sorting, for example, I probably would have settled for the familiar and natural selection sort. I wouldn't have bothered with the
more complex and efficient algorithms of merge and quick sorts. This course has changed my programming approach and has
equipped me well for future programming, especially with all the
tricks and tips taught to us throughout the semester. So, for helping me learn
how to code both correctly and efficiently, to Professor Danny, to my TAs, and
to my peers, I say: thank you! :)